I recently worked with my team, advising a customer on how to port their application from some other cloud into Google Cloud Platform.
One differentiator is Google AppEngine’s ability to quickly scale, absorbing sharp spikes in traffic, without requiring a “pre-warming” routine to maintain availability during sharp spikes. There was no way to predict a traffic spike for this use case. A large spike could happen at any time, a very different nature than most workloads which can rely on a forecast for peek traffic.
Another differentiator is Cloud PubSub, a global messaging service. An AppEngine instance in any region across the globe can publish and consume from PubSub with out requiring network gymnastics. Simply point the application at PubSub…Amazing!
The Microservice building block
AppEngine (GAE) combined with PubSub allows you to build your application in a very modular way. The cost of a new feature being implemented as a micro-service block can be forecast by the volume through PubSub and the number of GAE instances required.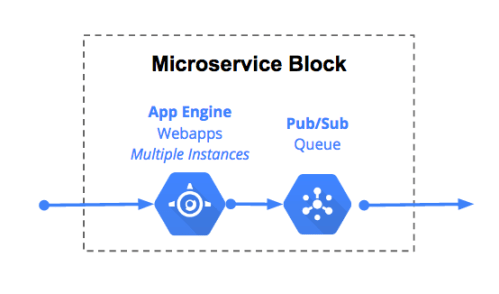
PubSub… More like Microservice hub
As you augment your application you end up with something similar to the picture below.
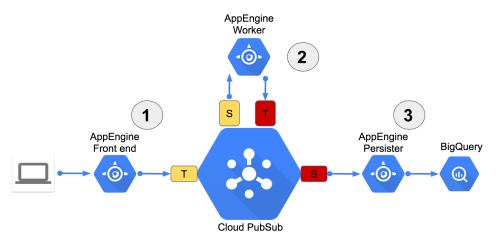
PubSub can contain 10K Topics and 10K Subscriptions!
1. Your front-end running GAE will take all the traffic from your clients. If there is a large surprise spike, no problem! GAE will quickly create new instances in less than a second. A topic on PubSub will be used by your front-end to push to subscribers.
2. The business logic running in GAE will have requests pushed at it from PubSub. This is the important part. PubSub can either be used to push or wait for a pull.
If you push, PubSub is targeting an endpoint. In this case the http/https endpoint for your worker application in GAE. This approach guarantees that each message will get handled only once and GAE will scale based on how fast your business logic workers can consume. The push is perfect for this use case.
If you pull, then each message could get handled by any worker subscribing to the topic, duplicating work. Also, in the pull model, you really can dictate the scaling of instances. Not really ideal in this use case.
3. Finally, we want to persist our work. In this example we are using GAE to write the messages into BigQuery. However, you could also use Dataflow to persist to BigQuery. If you are performing ETL, I recommend DataFlow.
Epic fail? No Sweat!
PubSub makes it easy to recover from a service disruption in your application. There are a a couple of key features.
- Messages persist for 7 days. PubSub will balloon up with messages. If you are pushing, then PubSub will continue attempting to push to your applications endpoint for 7 days.
- Messages aren’t removed until they are acknowledged. This allows you to implement exception handling for messages that can’t be process. Instead of creating a separate store for failed messages which must be reconciled, simply implement logging to alert you to the error and fix your code to handle the problem messages. If you are performing a pull this is done with ack/nack. If you are pushing this is done using the response code from the consumer. A response of 200,201,204 or 102 means success. Any other response and the message will be retried for 7 days.
Sample code?
Google provides a great example of how this works with Appengine and Pubsub. A couple of things to note about the sample code.
- The example code only uses one Appengine service that both pushes and consumes.
- The sample code pushes to PubSub with each request. You can batch the jobs to PubSub and get much better throughput. You can batch up to 1K message at a time. The snippet below shows you how to batch 900 messages.
if len(body["messages"]) < 900:
data = base64.b64encode(message.encode('utf-8'))
body["messages"].append(dict(data=data))
else:
data = base64.b64encode(message.encode('utf-8'))
body["messages"].append(dict(data=data))
topic_name = pubsub_utils.get_full_topic_name()
client.projects().topics().publish(topic=topic_name, body=body).execute()
del body["messages"][:]



 The
The